
Linode corrupted our server and how I got it back up

A few days ago, the server running Nomad List and Remote OK randomly went down. This is the timeline of what happened and how I fixed it.
All times are in Korean Standard Time.
21:05
Pieter starts messaging me on Telegram and I receive notifications from our uptime service. All of the sites are going down. Fearing a DDoS attack, Pieter enabled "Under Attack" mode on Cloudflare but it didn't fix the issue.
I tried to SSH into the server but I'm not getting anything back. SEWS (my server monitoring service) says load went up to 150 at 21:06 before failing to receive any more metrics. CPU usage had an increased amount of Waiting time (yellow), indicating the CPU was waiting for the disks.
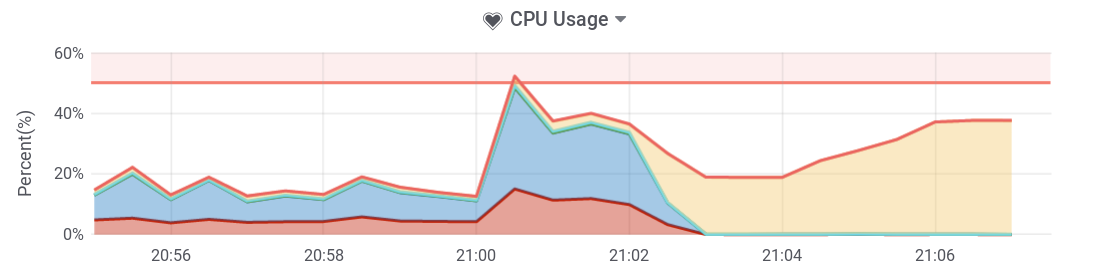
21:16
We received an email from Linode.
We have detected an issue affecting the physical host on which your Linode resides.
During this emergency maintenance:
- Your Linode may not be accessible.
- No action is required from your end at this time.
- We don't have an ETA on when your Linode will be brought back to its original state.
Once our administrators have completed the investigation, we will update this ticket with how we plan to proceed from here.
Your patience and understanding is greatly appreciated.
Ok, so it's not our fault. But it'd still be nice to get the server back up. I wait for the next communication...
21:31
The issue affecting your Linode's physical host has been resolved, and no further action is required at this time.
If your Linode was previously running, a boot job has been queued and your Linode will boot shortly. You can monitor the progress of your Linode's boot from the Dashboard tab within the Linode Manager.
During this maintenance, we've taken the steps to:
- Conduct a full investigation on the physical host to ensure its suitability for Linode services going forward.
- Log the event so we can fully understand the issue that occurred.
We understand downtime can be tough, so we would like to thank you for your patience and understanding throughout this emergency maintenance.
So Linode claims to have resolved the issue and the server reboots. Ok great, can't wait for the server to come back.
21:35
But it doesn't. I try SSHing into it and I'm still getting nothing. I open up Lish console within Linode and see these sad messages.
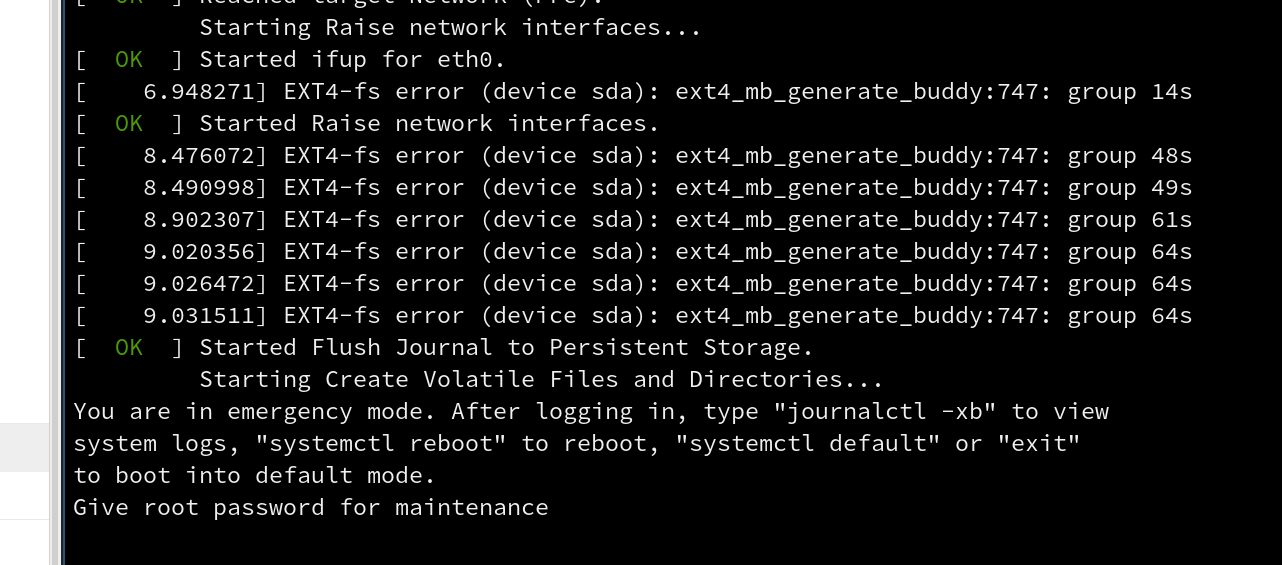
Oh no. This is bad. It looks like our filesystem is corrupt. I reboot the machine and get the same errors again.
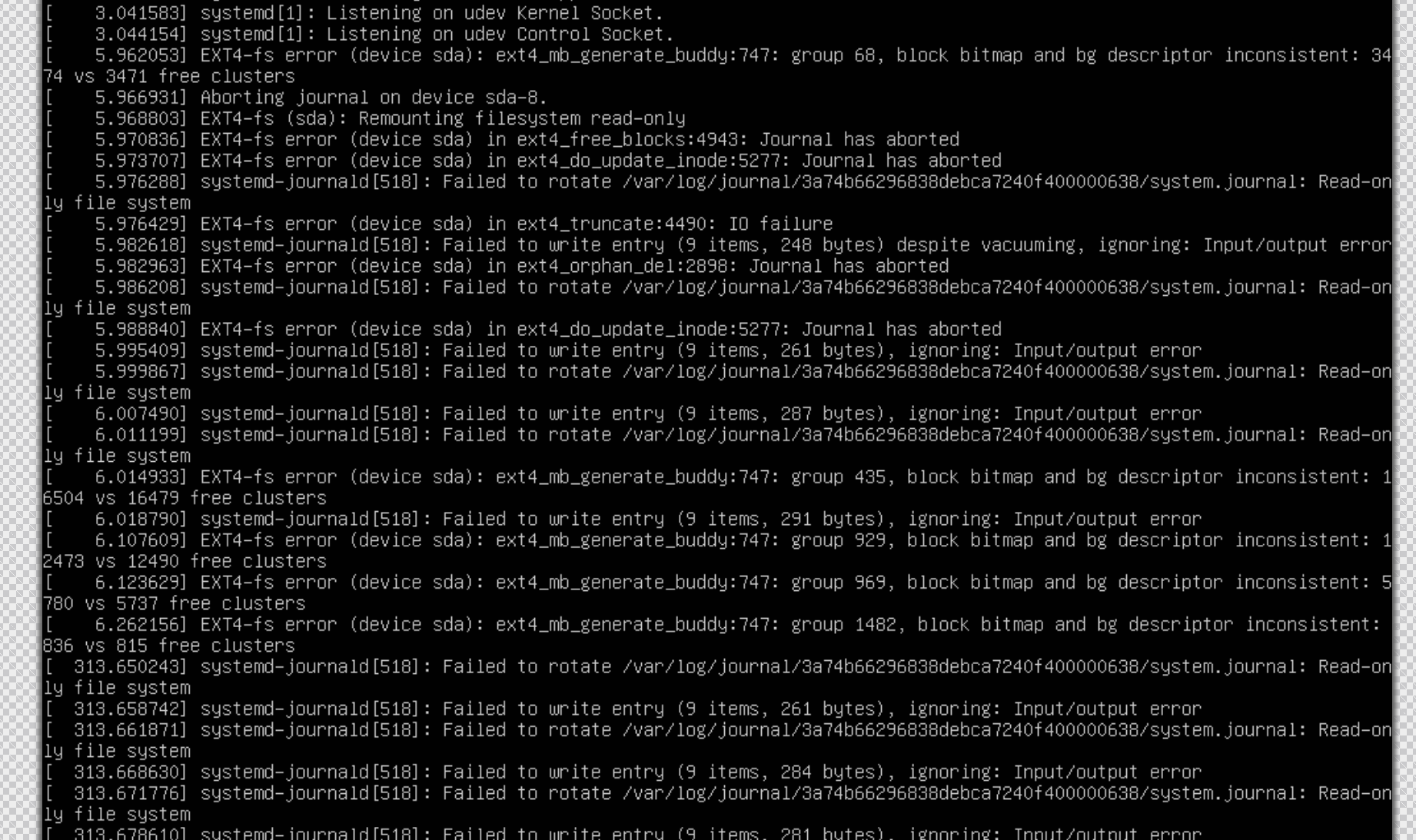
21:37
As soon as I saw these messages, I immediately sent support a message.
It looks like the disk or filesystem is corrupt. I am trying to boot the machine but it throws errors about EXT4.
We do have multiple full daily backups but it's not ideal and I'd like to get this server back up. Pieter has already tweeted about the issue to let people know, and although the server is non-critical, it tends to look bad if I don't fix it quickly.
I wait for 10 minutes to see if they get back to me. I don't get anything and I'm already uncomfortable with the downtime. So I go ahead and fix it myself. Linode has a panel within the dashboard where you can reboot into rescue mode. I let it reboot and then I can access it within the Lish console again.
I run fsck /dev/sda -y (fsck stands for file system consistency check) to start the repair procedure. It's pumping out a lot of messages related to disk corruption. It takes about 10 minutes to finish. I reboot the machine again.
22:03
The server comes back up! Excellent.
I wait for the uptime monitoring software to re-check everything. Most of the pages seem to be working.
However, it looks like we have a few corrupt SQLite databases and that was causing some of the pages to stay down. I take Nginx down and disable the cronjobs from within my cronlogger script to stop any further write attempts to the DBs. Luckily we have copies of the corrupt DBs in Backblaze. I can restore using the CLI tool and then re-run the scripts to update them. Seems to work!
I put everything back up and it looks like we're good. Mission success.
23:40
I finally get a response from Linode.
Sorry to hear this happened, but great to hear you got your Linode back up and running! Please let us know if you are still having problems and we will look into this for you.
Conclusion
Unfortunately, random downtime because of issues with the server hardware aren't something we can really avoid.
We did have the option of restoring a day old full backup to another server but I think the time it would have taken to restore the entire disk would have been longer than how long it took us to fix. Of course, if the disk was completely wrecked, I would have done that.
Several people were tweeting Pieter telling him he should have multiple redundancy and load balancing. Eh, I tend to agree with the comment below instead.
But again, cost v risk balance. In Pieters case, it sucks there was unplanned downtime, but the risk is minimal as this happens rarely. The cost of hosting a load balancer and increasing complexity is probably too high. He's not hosting critical infra, it's can tolerate downtime— Julian Nadeau (@jules2689) May 9, 2019
This is the first time it's happened in 5 years. And as the reply to that tweet says, "publish an yearly SLA of like 99.9% which allows you 9 hours of downtime a year". We had 1 hour.